

I Built a Tool that Creates a Weekly Newsletter Digest
I spent several hours on a prototype. Did it work?

Disclosure: This article was written by a human, me, with a technical review and light edit by Claude.
Honestly, this is a long article. If you just want to see the code and setup guide, you can find them on GitHub.
I've been on Substack for a couple of months now and, like everyone else, I went a little crazy with subscribing during my first couple of weeks. I don’t regret it, I love having access to so much amazing content, but I’ve been struggling to keep up with it all.
For a while, I’ve been meaning to create a Python script, or maybe a collection of agents, to grab all my newsletters every week or every day, surface a curated collection of interesting articles, and then list (and link) everything else, ideally grouped by category.
Curious to see if anyone else was thinking along the same lines, I wrote a Note about it. (If you’re new here, Notes is Substack’s Twitter-like social media platform.) It was my highest-performing Note by far:
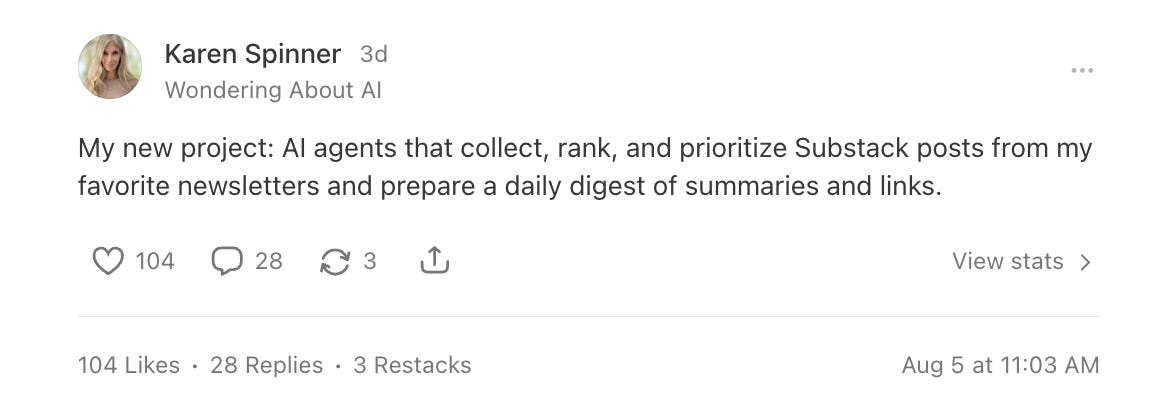
Most of the comments suggested that, indeed, this is a common problem.
Several people added that they were working on similar projects of their own. And some referenced this helpful tutorial from Peter Yang that uses n8n to extract newsletters from Gmail and create a weekly summary.
It was the jolt of motivation I needed to sketch out a rough specification for a prototype and start to build.
What would I build it with?
For simplicity and to keep costs low, I decided to use Python, RSS feeds (XML-formatted data streams that websites publish to make their content machine-readable), and my Claude API to build this project instead of trying n8n or another similar framework. Also, for speed and efficiency, I chose Claude as my coding engine.
Since I’m still trying to decide between Claude Code, Cursor, and Windsurf, I vibe-coded the old-fashioned way. This meant working in Anthropic’s Console, which lets me easily switch between models and set parameters like temperature and max tokens, and pasting code into the free Sublime editor for review and adjustment.
Automated vs agentic?
When I wrote my original Note about this project, I mentioned “AI agents” because I liked the idea of an “agent” proactively scanning for new content.
But, when I thought about it, I realized this probably wasn’t necessary, since digests will be produced once a week or once a day…certainly not in real time. I also realized that I didn’t want my newsletter digest bot operating independently, which could lead to it deciding on its own to skip over certain newsletters or articles.
I ultimately decided my newsletter digest bot would be an automation and not a true agent, at least for now.
Setting reasonable goals
As
Grab posts from the past seven days from a set of 20-30 test newsletters
Rate newsletters based on their length (as a proxy for depth) and engagement
Summarize the seven newsletters with the highest score
Group the remaining newsletters by category
List the remaining newsletters by title with links
Provide an attractively formatted HTML of the digest
A secondary goal was to mockup a UI for toggling between weekly and daily digests, adjusting the newsletter scoring criteria, and updating the list of newsletters.
Defining the workflow
With these goals in mind, I had an initial requirements-setting chat with Claude and sketched out a simple, rules-based workflow:
Measuring engagement (and scraping comments)
After more discovery with Claude, I focused on scraping comments from each article rather than likes. Substack’s like counts are loaded via JavaScript after the initial page render (client-side rendering), meaning they're not present in the raw HTML that basic HTTP requests retrieve.
Choosing a scoring method
To score the newsletters, I decided to keep it really simple and look at two main factors: how long the article is and how much people are engaging with it (through comments). Both are given equal importance.
Content length score (0-50 points)
Articles are scored based on their length. If an article has between 500 and 2000 words, it gets a full score (50 points). For every word, we give it a portion of the 50 points, but if it goes over 2000 words, the score is capped at 50 points (so no article gets more than that).Comment engagement score (0-50 points)
Articles are also scored based on how many comments they get. For each comment, the article earns 5 points, but this is capped at 50 points (so even if an article gets a lot of comments, it won't get more than 50 points). If there are no comments, the article gets 0 points here.Total score
The total score for the article is just the sum of the content length score and the comment engagement score. This gives us a final score between 0 and 100 points, which is rounded to two decimal places.
For future versions, I might include some kind of a relevance score based on keyword matching or contextual analysis.
Pulling it all together
At last, I was ready to ask Claude to create all the necessary functions for the newsletter digest, plus an orchestration function to run them in sequence. After a couple of rounds of iteration, here’s what we built:
load_processed_articles()
Loads previously processed articles from a JSON file to avoid reprocessing and duplication.save_processed_articles()
Saves the list of processed articles back into a JSON file to track articles that have been reviewed or featured.detect_paywall()
Checks if an article is behind a paywall by looking for common paywall indicators in the content or title.fetch_recent_articles()
Fetches articles from a list of RSS feeds, filtering by a specified timeframe (e.g., the last 7 days) and skipping already processed articles.extract_content()
Extracts the content from an RSS feed entry, cleaning up any HTML tags to return plain text.scrape_comments()
Scrapes the number of comments for an article by fetching the article page and looking for comment-related patterns in the page's content.categorize_newsletter()
Categorizes newsletters based on their source name into predefined categories like AI News, AI Research, Governance & Ethics, etc.generate_digest_html()
Generates an HTML digest with featured articles, additional articles grouped by category, and information on the articles such as quality score, comments, and summary.calculate_quality_score()
Calculates an article's quality score based on word count and comment engagement, with a higher score for more comments and content length within an ideal range.select_top_articles()
Selects the highest-quality articles based on their quality score, splitting them into featured and other articles.summarize_article()
Generates a summary of the article using the Claude API, focusing on key insights and developments.run_digest()
The main function that runs the entire digest generation process. It fetches recent articles, selects the top articles, generates summaries, creates the HTML digest, and saves the output. It also updates the list of processed articles.
Testing the script
When Claude’s script looked like it was probably going to run, it was time for testing. I set up a virtual environment on my local Mac to isolate the Newsletter Digest from all my other projects. (This is to make sure any new libraries I install don’t overwrite or interfere with libraries I installed for my existing projects.)
Fetching & parsing
feedparser — reads RSS feeds from AI newsletters.
requests — downloads article HTML.
BeautifulSoup (bs4) — parses HTML to extract titles, body, and comment counts.
Scoring & orchestration
datetime, time, re, json, os, typing, dataclasses — standard-library tools for timing, regex, storage, type hints, and lightweight data models.
pathlib.Path — file paths for outputs (HTML, JSON).
urllib.parse.urljoin — cleans up/normalizes URLs.
AI summarization
anthropic — calls Claude to generate concise summaries for the top articles.
python-dotenv (from dotenv import load_dotenv) — loads your CLAUDE_API_KEY from a local .env file so secrets aren’t hard-coded.
I also identified 28 newsletters, a small subset of the newsletters I subscribe to, as the test set.
OMG, it worked...well, mostly
After pulling posts from 28 newsletters, the script found 74 articles from the past week and accurately summarized seven of highest scoring pieces. It also listed every single post and grouped them into categories.
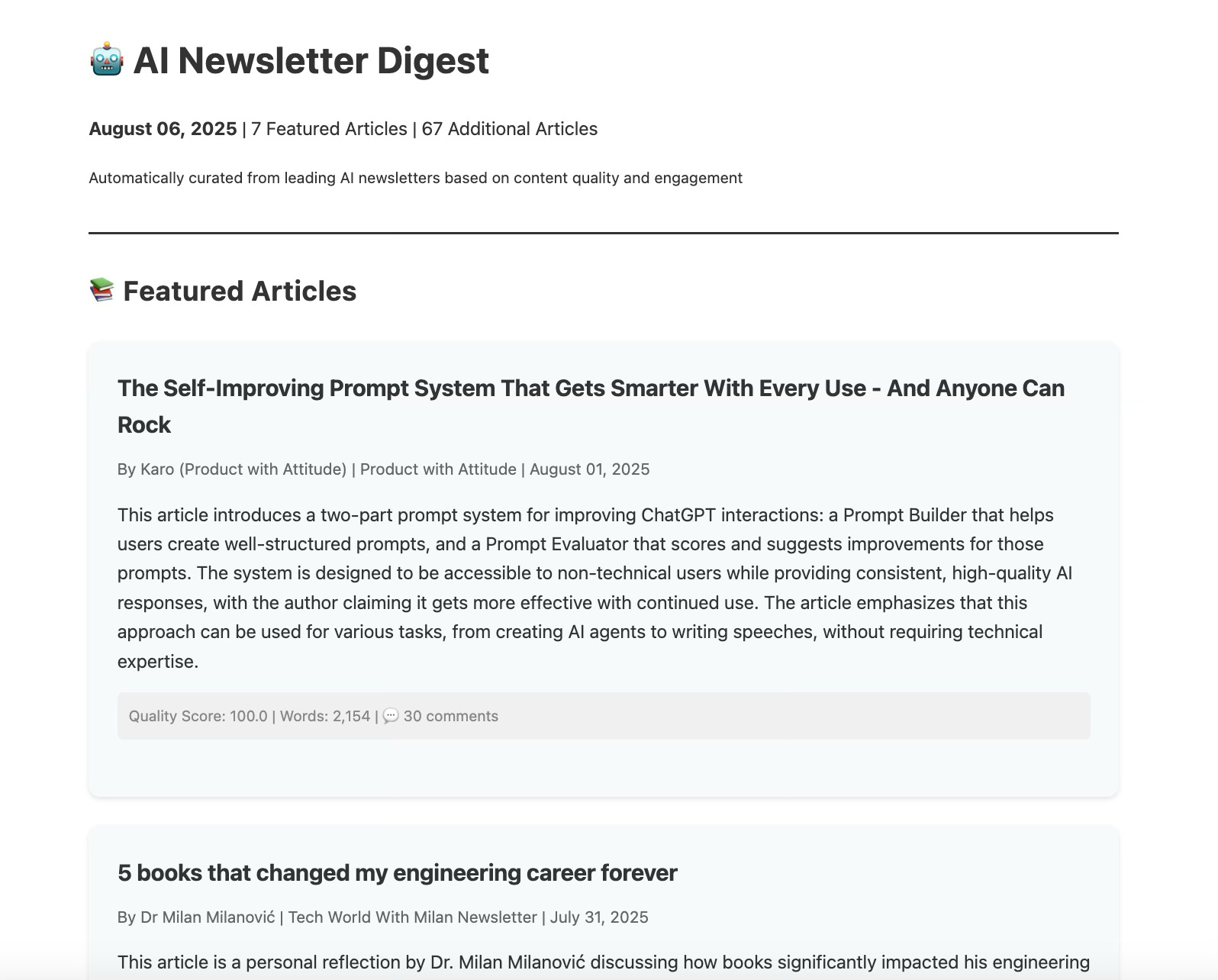
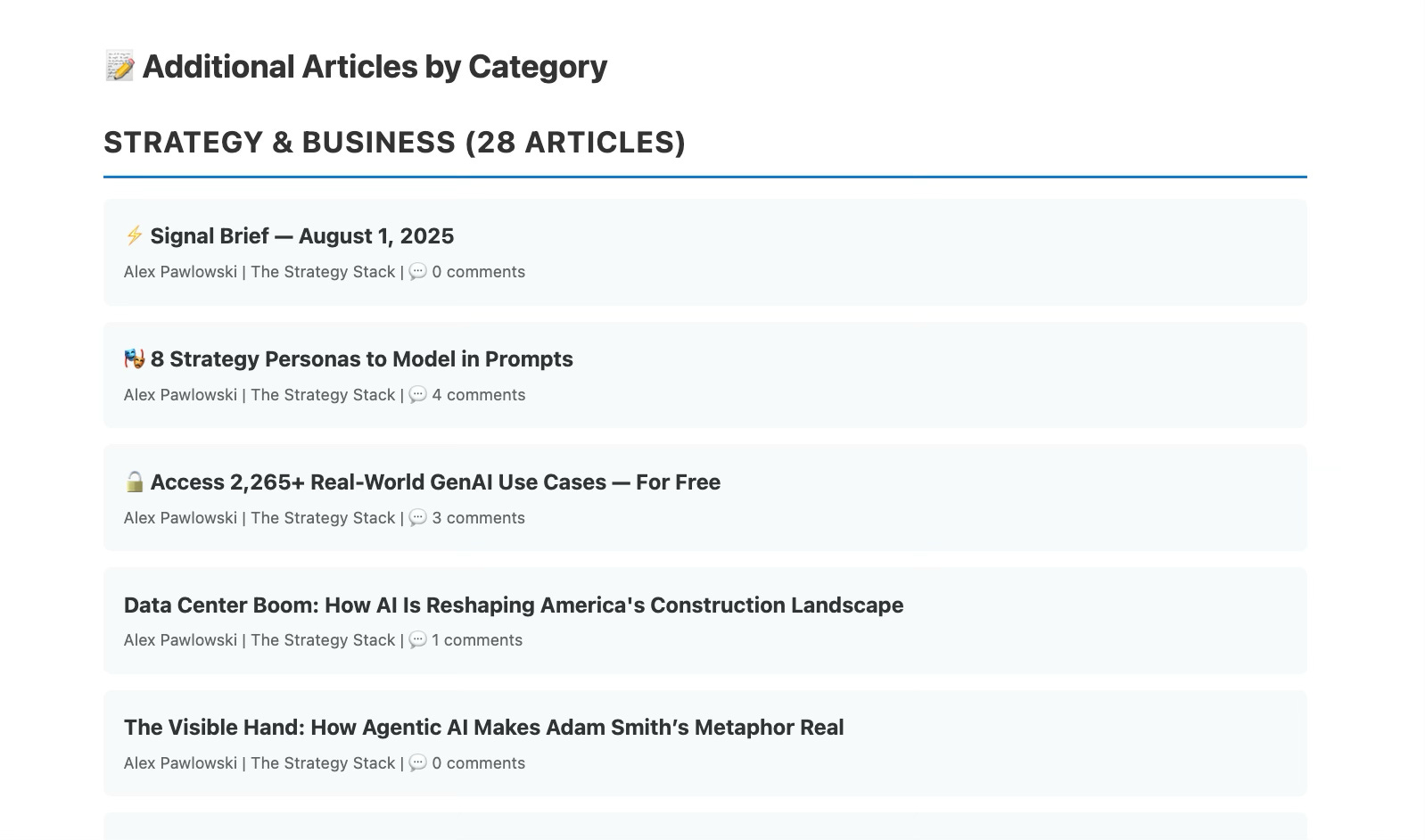
The categorization, perhaps because there was a lot of overlap between the articles, was imperfect. For the demo script you can see on GitHub, I simply assigned a category to each newsletter.
Thinking about what comes next
Once I had a working script that could successfully generate digests, I started thinking about how this concept could be generalized for other people. I brainstormed ideas using Claude and then visualized them in a rough HTML mock-up, which
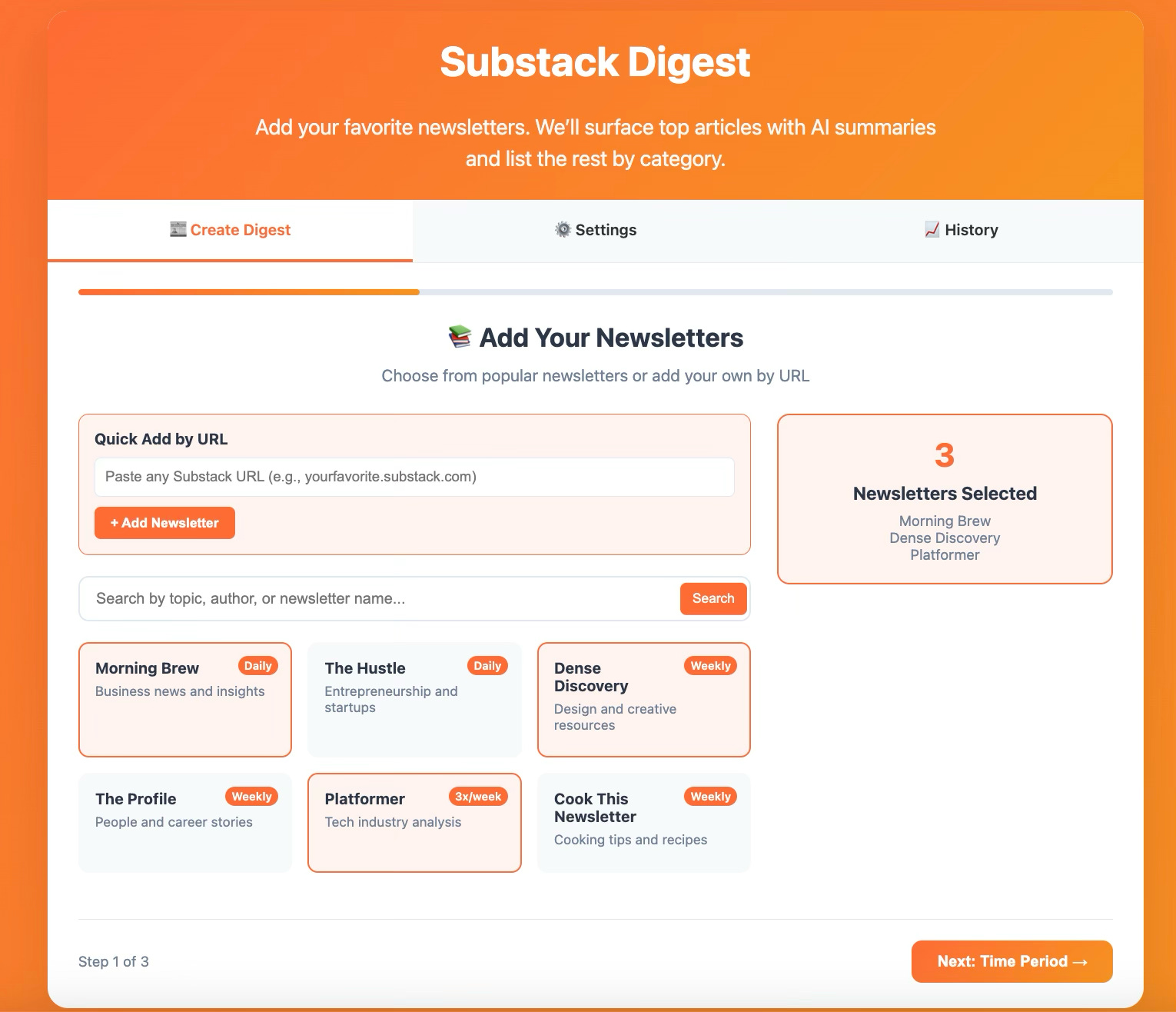
Step 1
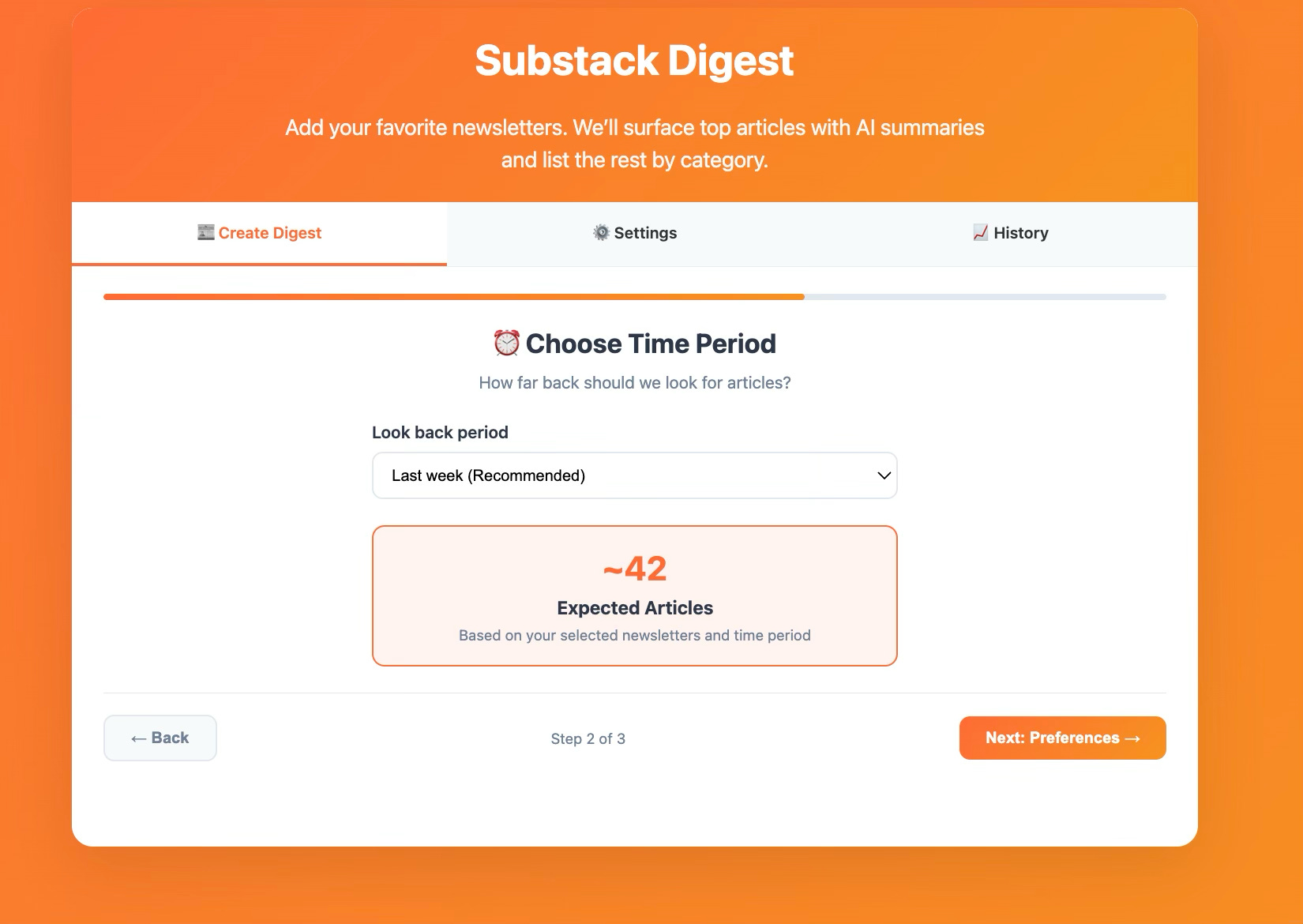
Step 2
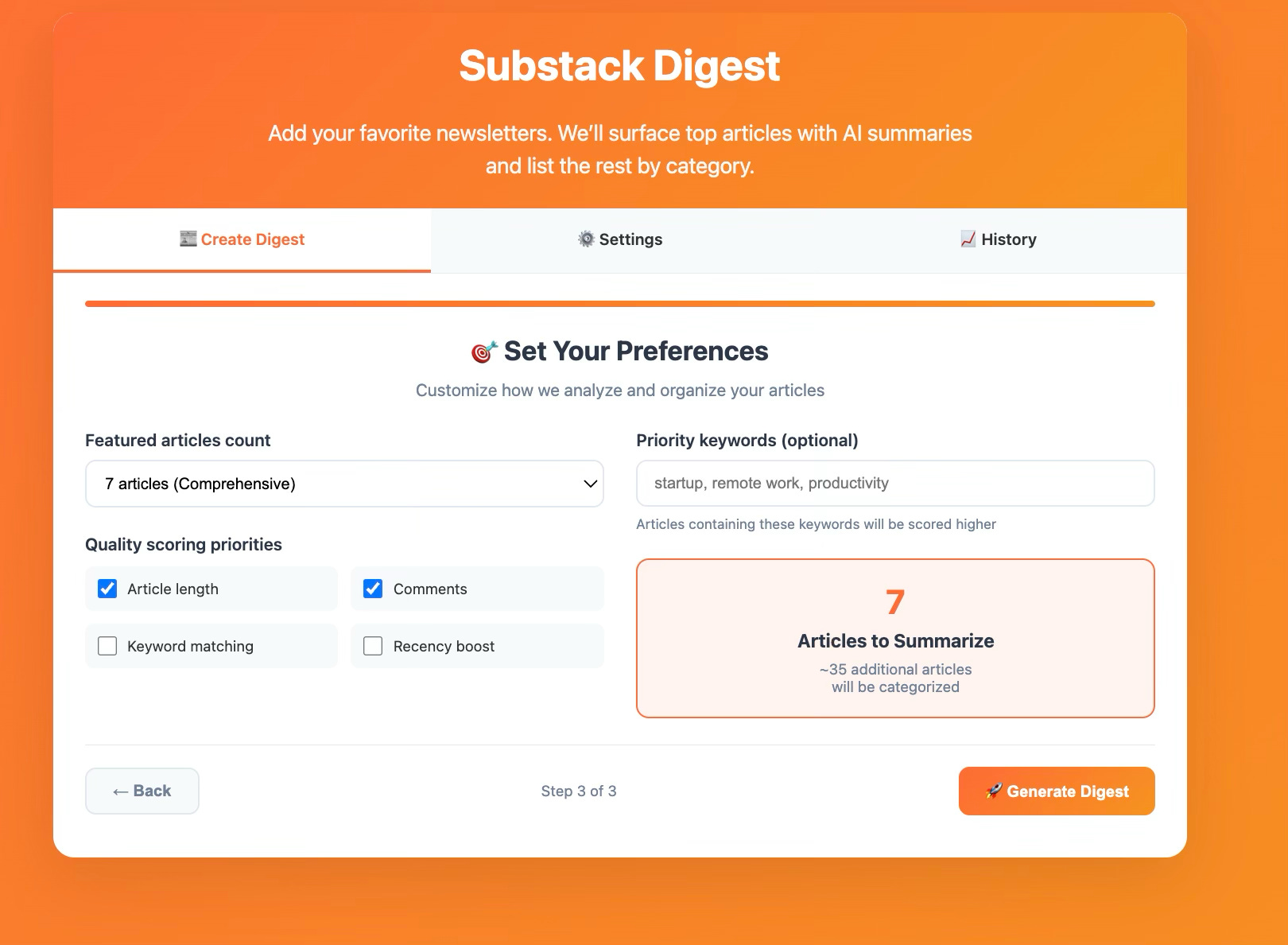
Step 3
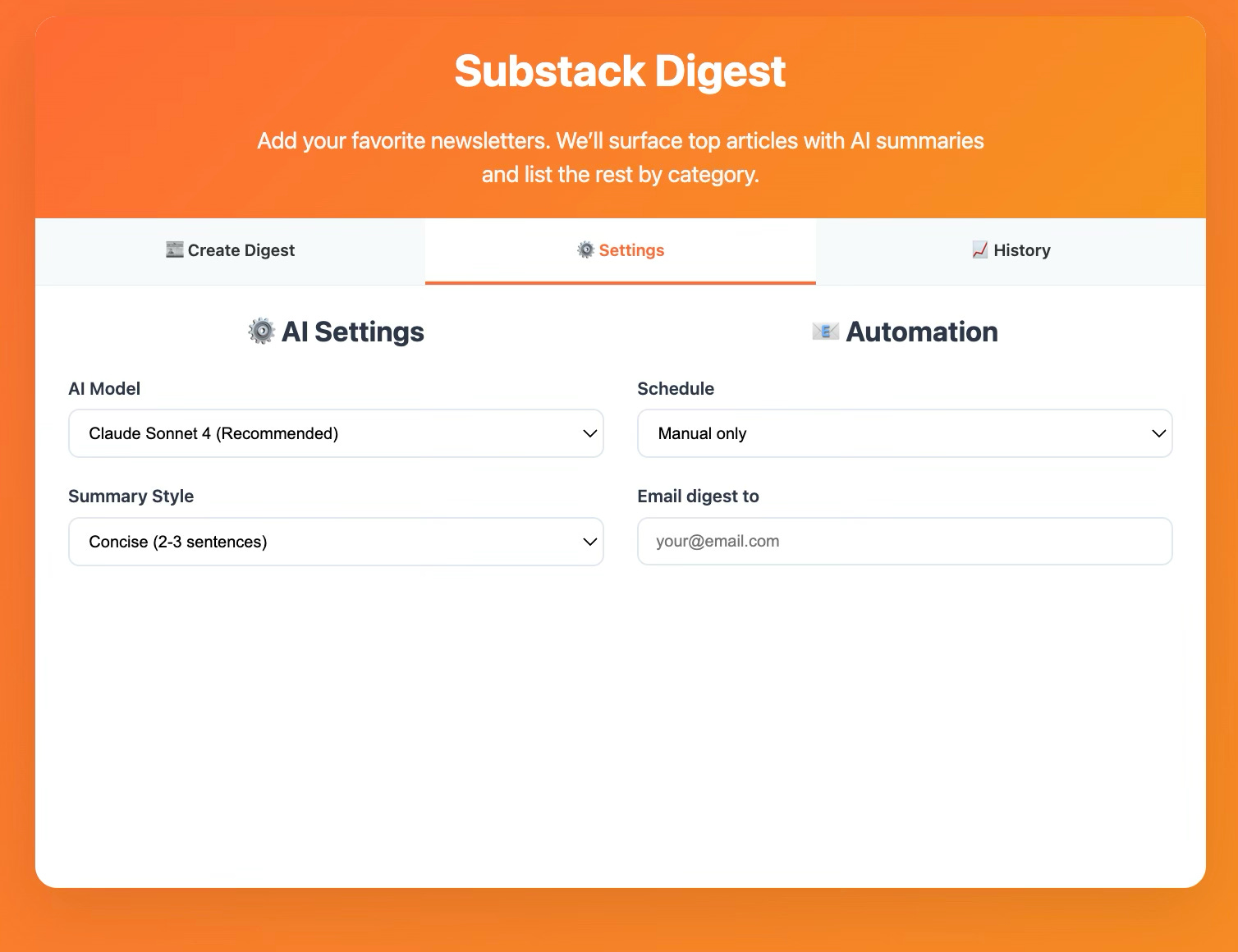
The mock-up also includes a Settings tab for AI model selection, summary preferences, and automation options, email delivery, plus a History tab that would track past digests and show usage analytics.
From project to product
Moving from “works for me” to “works for others” would require some…well, work. First, I would need to transition from JSON files to a real database to handle multiple users with different newsletter subscriptions and preferences.
Should I build it?
While I’m planning to tinker with the Python script a bit more, refine the summarization prompt, and test it with a truly large number of newsletters (300+), my existing script is functional and should be easy to adapt. You can find it, along with a sample digest, the HTML mock-up, and a setup guide on GitHub. If you build on this, I’d love to hear what you do.
If you’re interested in seeing this proof-of-concept turn into a product or service of some kind (and especially if you’d be interested in testing it), let me know. And definitely share your thoughts around what kinds of features you’d like to see!
Update: This proof-of-concept has evolved and is now up and running at https://stackdigest.io
We’re so grateful to
for allowing us to share her story here on Code Like A Girl. You can find her original post linked below.
If you enjoyed this piece, we encourage you to visit her publication and subscribe to support her work!
Join Code Like a Girl on Substack
We publish 2–3 times a week, bringing you:
Technical deep-dives and tutorials from women and non-binary technologists
Personal stories of resilience, bias, breakthroughs, and growth in tech
Actionable insights on leadership, equity, and the future of work
Since 2016, Code Like a Girl has amplified over 1,000 writers and built a thriving global community of readers. What makes this space different is that you’re not just reading stories, you’re joining a community of women in tech who are navigating the same challenges, asking the same questions, and celebrating the same wins.
Subscribe for free to get our stories, or become a paid subscriber to directly support this work and help us continue amplifying the voices of women and non-binary folks in tech.
 | A guest post by
|